
It’s fitting that my first article on Big Data would be titled the “Master Map-Reduce Job”. I believe it truly is the one and only Map-Reduce job you will every have to write, at least for ETL (Extract, Transform and Load) Processes. I have been working with Big Data and specifically with Hadoop for about two years now and I achieved my Cloudera Certified Developer for Apache Hadoop (CCDH) almost a year ago at the writing of this post.
So what is the Master Map-Reduce Job? Well it is a concept I started to architect that would become a framework level Map-Reduce job implementation that by itself is not a complete job, but uses Dependency Injection AKA a Plugin like framework to configure a Map-Reduce Job specifically for ETL Load processes.
Like most frameworks, you can write your process without them, however what the Master Map-Reduce Job (MMRJ) does is break down certain critical sections of the standard Map-Reduce job program into plugins that are named more specific to ETL processing, so it makes the jump from non-Hadoop based ETL to Hadoop based ETL easier for non-Hadoop-initiated developers.
I think this job is also extremely useful for the Map-Reduce pro who is implementing ETL jobs, or groups of ETL developers that want to create consistent Map-Reduce based loaders, and that’s the real point of the MMRJ. To create a framework for developers to use that will enable them to create robust, consistent, and easily maintainable Map-Reduce based loaders. It follows my SFEMS – Stable, Flexible, Extensible, Maintainable, Scalable development philosophy.
The point of the Master Map Reduce concept framework is to breaks down the Driver, Mapper, and Reducer into parts that non-Hadoop/Map-Reduce programmers are well familiar with; especially in the ETL world. It is easy for Java developers who build Loaders for a living to understand vocabulary like Validator, Transformer, Parser, OutputFormatter, etc. They can focus on writing business specific logic and they do not have to worry about the finer points of Map-Reduce.
As a manager you can now hire a single senior Hadoop/Map-Reduce developer and hire normal core Java developers for the rest of your team or better yet reuse your existing team and you can have the one senior Hadoop developer maintain your version of the Master Map-Reduce Job framework code, and the rest of your developers focus on developing feed level loader processes using the framework. In the end all developers can learn Map-Reduce, but you do not need to know Map-Reduce to get started writing loaders that will work on the Hadoop cluster by using this framework.
The design is simple and can be show by this one diagram:
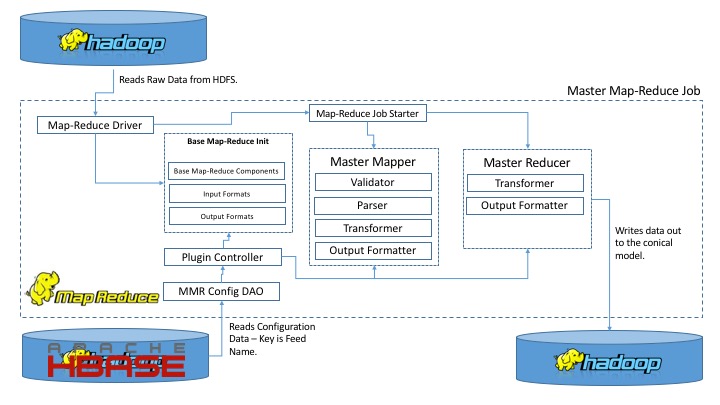
One of the core concepts that separates the Master Map-Reduce Job Conceptual Framework from a normal Map-Reduce Job, is how the Mapper and Reducer are structured and the logic that normally would be written directly in the map and reduce functions are now externalized into classes that use vocabulary that is natively familiar to ETL Java Developers, such as Validator, Parser, Transformer, Output Formatter. It is this externalization that simplifies the ETL job Map-Reduce development. I believe that what confuses developers about how to make Map-Reduce jobs work as robust ETL processes is that it’s too low level. You take a look at a map function and a reduce function, and a developer who does not have experience with writing complex map-reduce jobs, will take one look and say it’s too low level and perhaps even I’m not sure exactly what they expect me to do with this. Developers can be quickly turned off by the raw low level interface, although tremendously power that Map-Reduce exposes.
It is this code below that makes the most valuable architectural asset of the framework. The fact that we in the Master Map-Reduce Job Conceptual Framework have broken down the map method of the Mapper class into a very simple process flow of FIVE steps that will make sense to any ETL Developer. Please read through the comments, for each step. Also note that the same thing is done for the Reducer, but only the Transform and Output Formatter are used.
Map Function turn into a ETL Process Goldmine:
@Override
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String record;
String[] fields;
try {
//First validate the record
record = value.toString();
if (validator.validateRecord(record)) {
//Second Parse valid records into fields
fields = (String[]) parser.parse(record);
//Third validate individual tokens or fields
if (validator.validateFields(fields)) {
//Fourth run transformation logic
fields = (String[]) transformer.runMapSideTransform(fields);
//Fifth output transformed records
outputFormatter.writeMapSideFormat(key, fields, output);
}
else {
//One or more fields are invalid!
//For now just record that
reporter.getCounter(MasterMapReduceCounters.VALIDATION_FAILED_RECORD_CNT).increment(1);
}
} //End if validator.validateRecord
else {
//Record is invalid!
//For now just record, but perhaps more logic
//to stop the loader if a threshold is reached
reporter.getCounter(MasterMapReduceCounters.VALIDATION_FAILED_RECORD_CNT).increment(1);
}
} //End try block
catch (MasterMapReduceException e) {
throw new IOException(e);
}
}
Source Code for the Master Map-Reduce Concept Framework:
The source code here should be considered a work in progress. I make no statements to if this actually works, nor has it been stress tested in anyway, and should only be used as a reference. Do not use it directly in mission critical or production applications.
All Code on this page is released under the following open source license:
Copyright 2016 Robert C. Ilardi
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
MasterMapReduceDriver.java – This class is a generic Map-Reduce Driver program, which makes use of two classes from the MasterMapReduce concept framework, which are the “MasterMapReduceConfigDao” and “PluginController”. Both are responsible for returning configuration data to the MasterMapReduceDriver, as well as (we will see later on) the Master Mapper and Master Reducer. The MasterMapReduceConfigDao, is a standard Data Access Object implementation that wraps data access to HBase, where configuration tables are created that make use of a “Feed Name” as the row keys, and have various columns that represent class names, or other configuration information such as Job Name, Reducer Task number, etc. The PluginController is a higher level wrapper around the DAO itself, whereas the DAO is responsible for low level data access to HBase, the PluginController, does the class creation and other high level functions that make use of the data returned by the DAO. We do not present the implementations for the DAO or the PluginController here because they are simple PoJos that you should implement based on your configuration strategy. Instead of HBase for example, it can be done via a set of plain text files on HDFS or even the local file system.
The Master Map Reduce Driver is responsible for setting up the Map-Reduce Job just like any other standard Map-Reduce Driver. The main difference is that it has been written to make use the Plugin architecture to configure the job’s parameters dynamically.
/**
* Created Feb 1, 2016
*/
package com.roguelogic.mrloader;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author Robert C. Ilardi
*
*/
public class MasterMapReduceDriver extends Configured implements Tool {
public static final String MMR_FEED_NAME = "RL.MasterMapReduce.FeedName";
private MasterMapReduceConfigDao confDao;
private PluginController pluginController;
private String feedName;
private String mmrJobName;
private String inputPath;
private String outputPath;
public MasterMapReduceDriver() {
super();
}
public synchronized void init(String feedName) {
System.out.println("Initializing MasterMapReduce Driver for Feed Name: " + feedName);
this.feedName = feedName;
//Create MMR Configuration DAO (Data Access Object)
confDao = new MasterMapReduceConfigDao();
confDao.init(feedName); //Initialize Config DAO for specific Feed Name
//Read Driver Level Properties
mmrJobName = confDao.getLoaderJobNameByFeedName();
inputPath = confDao.getLoaderJobInputPath();
outputPath = confDao.getLoaderJobOutputPath();
//Configure MMR Plugin Controller
pluginController = new PluginController();
pluginController.setConfigurationDao(confDao);
pluginController.init();
}
@Override
public int run(String[] args) throws Exception {
JobConf jConf;
Configuration conf;
int res;
conf = getConf();
jConf = new JobConf(conf, this.getClass());
jConf.setJarByClass(this.getClass());
//Set some shared parameters to send to Mapper and Reducer
jConf.set(MMR_FEED_NAME, feedName);
configureBaseMapReduceComponents(jConf);
configureBaseMapReduceOutputFormat(jConf);
configureBaseMapReduceInputFormat(jConf);
res = startMapReduceJob(jConf);
return res;
}
private void configureBaseMapReduceInputFormat(JobConf jConf) {
Class clazz;
clazz = pluginController.getInputFormat();
jConf.setInputFormat(clazz);
FileInputFormat.setInputPaths(jConf, new Path(inputPath));
}
private void configureBaseMapReduceOutputFormat(JobConf jConf) {
Class clazz;
clazz = pluginController.getOutputKey();
jConf.setOutputKeyClass(clazz);
clazz = pluginController.getOutputValue();
jConf.setOutputValueClass(clazz);
clazz = pluginController.getOutputFormat();
jConf.setOutputFormat(clazz);
FileOutputFormat.setOutputPath(jConf, new Path(outputPath));
}
private void configureBaseMapReduceComponents(JobConf jConf) {
Class clazz;
int cnt;
//Set Mapper Class
clazz = pluginController.getMapper();
jConf.setMapperClass(clazz);
//Optionally Set Custom Reducer Class
clazz = pluginController.getReducer();
if (clazz != null) {
jConf.setReducerClass(clazz);
}
//Optionally explicitly set number of reducers if available
if (pluginController.hasExplicitReducerCount()) {
cnt = pluginController.getReducerCount();
jConf.setNumReduceTasks(cnt);
}
//Set Partitioner Class if a custom one is required for this Job
clazz = pluginController.getPartitioner();
if (clazz != null) {
jConf.setPartitionerClass(clazz);
}
//Set Combiner Class if a custom one is required for this Job
clazz = pluginController.getCombiner();
if (clazz != null) {
jConf.setCombinerClass(clazz);
}
}
private int startMapReduceJob(JobConf jConf) throws IOException {
int res;
RunningJob job;
job = JobClient.runJob(jConf);
res = 0;
return res;
}
public static void main(String[] args) {
int exitCd;
MasterMapReduceDriver mmrDriver;
Configuration conf;
String feedName;
if (args.length < 1) {
exitCd = 1;
System.err.println("Usage: java " + MasterMapReduceDriver.class + " [FEED_NAME]");
}
else {
try {
feedName = args[0];
conf = new Configuration();
mmrDriver = new MasterMapReduceDriver();
mmrDriver.init(feedName);
exitCd = ToolRunner.run(conf, mmrDriver, args);
} //End try block
catch (Exception e) {
exitCd = 1;
e.printStackTrace();
}
}
System.exit(exitCd);
}
}
Code Formatted by ToGoTutor
BaseMasterMapper.java – This class is an abstract base class that implements the configure method of the Mapper implementation, to make use of the DAO and PluginController already described above. It should be extended by all your Mapper implementations you use when creating a Map-Reduce job using the Master Map Reduce concept framework. In the future we might create additional helper functions in this class for the mappers to use. In the end you only need a finite number of Mapper implementations. It is envisioned that the number of mappers is related more to the number of file formats you have, not the number of feeds. The idea of the framework is not to have to write the lower level components of a Map-Reduce job at the feed level, and instead developers should focus on the business logic such as Validation logic and Transformation logic. The fact that this logic runs in a Map-Reduce job is simply because it needs to run on the Hadoop cluster. Otherwise these loader jobs execute logic like any other standard Loader job running outside of the Hadoop cluster.
/**
* Created Feb 1, 2016
*/
package com.roguelogic.mrloader;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
/**
* @author Robert C. Ilardi
*
*/
public abstract class BaseMasterMapper extends MapReduceBase {
protected String feedName;
protected MasterMapReduceConfigDao confDao;
protected PluginController pluginController;
protected Validator validator; //Used to validate Records and Fields
protected Parser parser; //Used to parse records into fields
protected Transformer transformer; //Used to run transformation logic on fields
protected OutputFormatter outputFormatter; //Used to write out formatted records
public BaseMasterMapper() {
super();
}
@Override
public void configure(JobConf conf) {
feedName = conf.get(MasterMapReduceDriver.MMR_FEED_NAME);
confDao = new MasterMapReduceConfigDao();
confDao.init(feedName);
pluginController = new PluginController();
pluginController.setConfigurationDao(confDao);
pluginController.init();
validator = pluginController.getValidator();
parser = pluginController.getParser();
transformer = pluginController.getTransformer();
outputFormatter = pluginController.getOutputFormatter();
}
}
Code Formatted by ToGoTutor
BaseMasterReducer.java – Just like on the Mapper side, this class is the base class for all Reducers implementations that are used with the Master Map-Reduce Job framework. Like the BaseMasterMapper class it implements the configure method and provides access to the DAO and PluginController for reducer implementations. Again in the future we may expand this to include additional helper functions.
/**
* Created Feb 1, 2016
*/
package com.roguelogic.mrloader;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
/**
* @author Robert C. Ilardi
*
*/
public abstract class BaseMasterReducer extends MapReduceBase {
protected String feedName;
protected MasterMapReduceConfigDao confDao;
protected PluginController pluginController;
protected Transformer transformer; //Used to run transformation logic on fields
protected OutputFormatter outputFormatter; //Used to write out formatted records
public BaseMasterReducer() {
super();
}
@Override
public void configure(JobConf conf) {
feedName = conf.get(MasterMapReduceDriver.MMR_FEED_NAME);
confDao = new MasterMapReduceConfigDao();
confDao.init(feedName);
pluginController = new PluginController();
pluginController.setConfigurationDao(confDao);
pluginController.init();
transformer = pluginController.getTransformer();
outputFormatter = pluginController.getOutputFormatter();
}
}
Code Formatted by ToGoTutor
StringRecordMasterMapper.java – This is a example implementation of what a Master Mapper implementation would look like. Note that it has nothing to do with the Feed, instead it is related to the file format. Specifically this class would make sense as a mapper for a delimited text file format.
/**
* Created Feb 1, 2016
*/
package com.roguelogic.mrloader;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
/**
* @author Robert C. Ilardi
*
*/
public class StringRecordMasterMapper extends BaseMasterMapper implements Mapper {
public StringRecordMasterMapper() {
super();
}
@Override
public void map(LongWritable key, Text value, OutputCollector output, Reporter reporter) throws IOException {
String record;
String[] fields;
try {
//First validate the record
record = value.toString();
if (validator.validateRecord(record)) {
//Second Parse valid records into fields
fields = (String[]) parser.parse(record);
//Third validate individual tokens or fields
if (validator.validateFields(fields)) {
//Fourth run transformation logic
fields = (String[]) transformer.runMapSideTransform(fields);
//Fifth output transformed records
outputFormatter.writeMapSideFormat(key, fields, output);
}
else {
//One or more fields are invalid!
//For now just record that
reporter.getCounter(MasterMapReduceCounters.VALIDATION_FAILED_RECORD_CNT).increment(1);
}
} //End if validator.validateRecord
else {
//Record is invalid!
//For now just record, but perhaps more logic
//to stop the loader if a threshold is reached
reporter.getCounter(MasterMapReduceCounters.VALIDATION_FAILED_RECORD_CNT).increment(1);
}
} //End try block
catch (MasterMapReduceException e) {
throw new IOException(e);
}
}
}
Code Formatted by ToGoTutor
StringRecordMasterReducer.java – This is an example implementation of what the Master Reducer would look like. It compliments the StringRecordMasterMapper from above, in that it works well with text line / delimited file formats. The idea here is that the Mapper parses and transforms raw feed data into a conical data model and outputs that transformed data in a similar delimited text file format. Most likely the Reducer implementation can simply be a pass through. It’s possible that a reducer in this case is not even needed, and we can configure the Master Map Reduce Driver to be a Map-Only job.
/**
* Created Feb 1, 2016
*/
package com.roguelogic.mrloader;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
/**
* @author Robert C. Ilardi
*
*/
public class StringRecordMasterReducer extends BaseMasterReducer implements Reducer {
public StringRecordMasterReducer() {
super();
}
@Override
public void reduce(LongWritable key, Iterator values, OutputCollector output, Reporter reporter) throws IOException {
String data;
Text txt;
try {
while (values.hasNext()) {
txt = values.next();
data = txt.toString();
//First run transformation logic
data = (String) transformer.runReduceSideTransform(data);
//Second output transformed records
outputFormatter.writeReduceSideFormat(data, output);
} //End while (values.hasNext())
} //End try block
catch (MasterMapReduceException e) {
throw new IOException(e);
}
}
}
Code Formatted by ToGoTutor
Conclusion
In the end, some make ask how much value those a framework like this add? Isn’t Map-Reduce simple enough? Well the truth is, we need to ask this for all frameworks and wrappers we use. Are their inclusion worth it? I think in this case the Master Map Reduce framework does add value. It breaks down the Driver, Mapper, and Reducer into parts that non-Hadoop/Map-Reduce programmers are well familiar with; especially in the ETL world. It is easy for Java developers who build Loaders for a living to understand vocabulary like Validator, Transformer, Parser, OutputFormatter, etc. They can focus on writing business specific logic and they do not have to worry about the finer points of Map-Reduce. Combine this with the fact that this framework creates an environment where you can create hundreds of Map-Reduce programs, one for each feed you are loading, and each program will have the exact same Map-Reduce structure, I believe this framework is well worth it.
Just Another Stream of Random Bits… – Robert C. Ilardi